Why your data quality rules engine is failing and how to fix it?
As enterprises centralize data to support AI and analytics, enforcing consistent, scalable data quality rules has become increasingly difficult. Enterprises need a simpler way to manage data quality rules as traditional methods fall short at scale. Evolving business logic and complex data environments demand a more flexible, unified approach.

As enterprises consolidate data from multiple sources into data lakes to make it AI-ready, different teams consuming this data apply business rules and processes to ensure it meets their specific needs. Individual data products often require unique rules that structure, validate, and govern how the data is used.
To support these varied needs, data engineering teams require a framework that applies business logic effectively and ensures both data integrity and operational efficiency. This is where data quality (DQ) rules come into play.
Many data teams build homegrown rule engines or use SQL-based validation to enforce data quality checks. However, as data volumes grow and business rules evolve, these traditional approaches quickly become bottlenecks. This makes it harder to scale data quality management.
So, what’s wrong with the current approach to data quality rules? And how can enterprises move toward a more efficient, scalable solution?
Why companies should rethink their approach to data quality rules
Enterprises have implemented Data Quality (DQ) rules using two primary approaches:
- Building homegrown rule engines – Custom-built systems designed to enforce data validation within an organization’s unique architecture.
- DQ platforms supporting pushdown processing – Using off-the-shelf solutions to run DQ checks directly within databases, data lakes, and cloud warehouses using SQL queries or distributed query engines.
These approaches may have worked in the past. But as data volumes grow and business logic becomes more complex, they introduce significant scalability and performance challenges:
- No unified interface for rule management across storage systems–Enterprises manage data across diverse storage systems, but vendors often build rule engines for specific platforms, forcing teams to implement separate solutions for data lakes, cloud warehouses, and other environments.. Without a unified interface, teams must manually define, modify, and enforce rules for each system, making governance complex and increasing operational overhead. Architectural changes further complicate rule portability, adding engineering effort and slowing adoption across hybrid and multi-cloud environments.
- Compute overhead & performance bottlenecks –Homegrown DQ rule engines or vendor solutions that rely on SQL-based checks push computation down to the underlying data platform, consuming expensive processing resources. The more complex the validation logic, the higher the query execution time and infrastructure costs, especially when applied across high-volume streaming or batch workflows.
- Reactive rather than Proactive monitoring– Most existing rule engines operate in a batch-oriented manner, applying validation only after data has landed in storage or during predefined ETL/ELT cycles. This delayed validation approach allows errors to propagate downstream before they are detected, leading to costly reprocessing and manual intervention.
- The complexity of managing rule variability- Different teams within an organization often define rules independently, leading to inconsistencies in how data quality is measured and enforced. Without a centralized rules management system, businesses struggle with:
- Conflicting validation logic across departments
- Lack of visibility into which rules are applied to which datasets
- Difficulty in tracking changes, auditing decisions, and ensuring compliance
Additionally, many legacy systems require extensive engineering effort, making rule management a high-maintenance, low-agility process. As a result, data teams spend more time maintaining rule engines than improving data quality itself—an operational burden that only worsens as enterprises scale.
So, how can organizations eliminate these inefficiencies and transition to a more scalable, business-friendly approach?
Ensuring data quality is made simple for Business and Engineering teams
As enterprises scale, data quality rule enforcement must evolve beyond traditional, engineering-heavy methods. Data quality ownership needs to be democratized, enabling users to manage data quality without requiring coding expertise or manual intervention.
To address these challenges, Telmai has developed a modern, scalable rules engine that empowers both business and engineering teams, enabling them to define, manage, and enforce DQ rules without infrastructure bottlenecks or performance trade-offs. Telmai’s new rules engine is designed to:
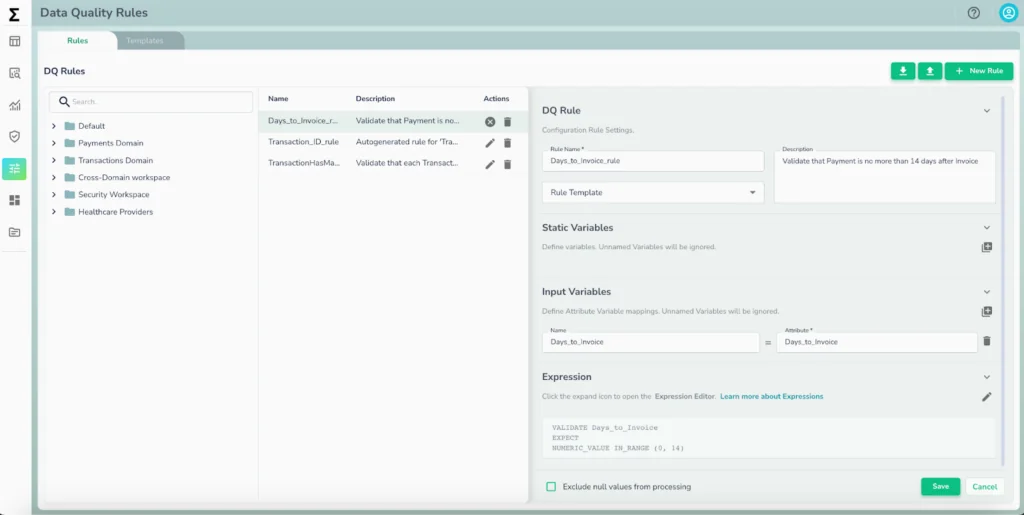
- Make DQ rule enforcement accessible- Telmai’s Intuitive, no-code user interface allows business users and data teams to define and manage data quality rules without engineering dependencies. This democratization of rule enforcement ensures that validation is accessible to domain experts and operational teams, reducing reliance on technical resources.
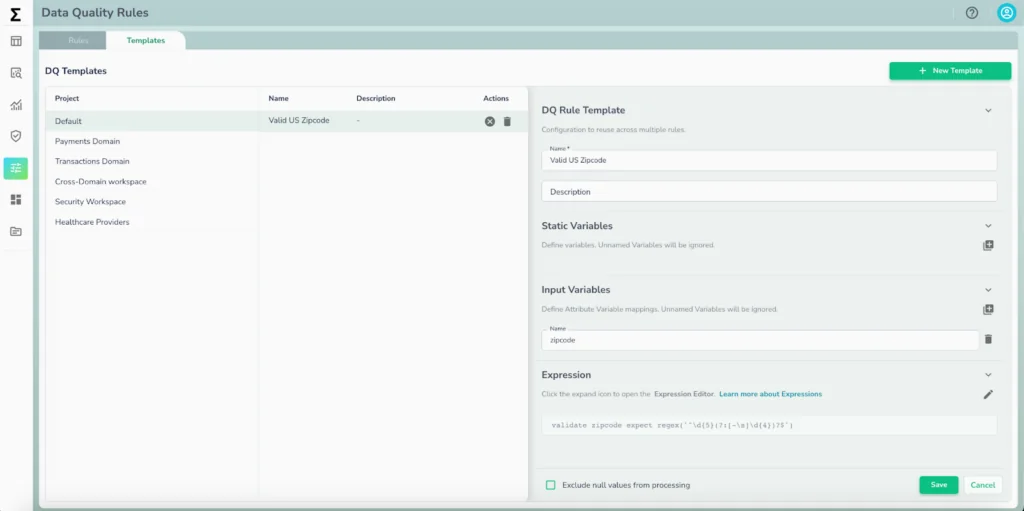
- Code-based flexibility for data teams- For data engineers and technical teams, Telmai provides a JSON-based rule definition framework, allowing rules to be:
- Templatized – Engineers can reuse and standardize validation logic across datasets
- Automated – Rules can be applied and integrated into CI/CD workflows
- Version-Controlled – Enables rule tracking, auditing, and rollback when necessary
Engineers can seamlessly integrate rules via APIs, ensuring validation logic remains consistent across data pipelines.
- Optimized execution layer for performance & cost efficiency- Unlike SQL-based rule execution, which pushes computation to data warehouses, lakes, or distributed engines, Telmai’s engine decouples rule execution from storage, ensuring:
- Minimal impact on storage and query performance
- Efficient rule execution without adding database overhead
- Real-time validation across structured and semi-structured data
- Migration & adoption of DQ rules across systems made simple- Telmai enables configuration-as-code, allowing enterprises to map legacy rule logic by importing and modifying existing rules—eliminating the need for costly rule rewrites. Enterprises like ZoomInfo, which operate in multi-cloud environments, have successfully migrated to Telmai with faster time to value and minimal disruption.
- Real-time, scalable data quality validation- Telmai’s rules engine supports both batch and streaming data validation, allowing organizations to proactively detect anomalies instead of waiting for batch ETL jobs and Apply rules dynamically across evolving datasets and schema changes, reducing operational disruptions
Take the next step toward scalable data quality
Traditional data quality rule enforcement is rigid, inefficient, and expensive. It struggles to keep up with the scale and pace of modern data environments. As enterprises grow, they need a more flexible and scalable way to define, manage, and enforce DQ rules. They must achieve this without running into engineering bottlenecks or infrastructure limitations.
See how Telmai can help your organization simplify and automate data quality at an enterprise scale. Click here to talk to our team of experts today.
Passionate about data quality? Get expert insights and guides delivered straight to your inbox – click here to subscribe to our newsletter now.
- On this page
See what’s possible with Telmai
Request a demo to see the full power of Telmai’s data observability tool for yourself.