Why sampling falls short in ensuring reliable data systems
Performing data quality checks on a sample of your dataset can miss critical anomalies and cause costly delays. Discover how full-fidelity analysis revolutionizes accuracy and efficiency, ensuring your insights are always reliable and your data is trustworthy.

Introduction
Imagine putting together a piece of furniture with only part of the instructions. You might get some parts right, but the final product could be wobbly or even unsafe. Now, think about how crucial your data is for business operations. Ensuring the quality of your entire dataset by only checking a small portion is just as risky. Would you trust that approach? Reports that poor data quality costs companies an average of $12.9 million each year. It’s not just about spotting immediate issues but also about planning for the future and making sure solutions can grow with your needs. Large amounts of data can overwhelm traditional data quality tools, making it essential to have robust, scalable solutions. In this article, we’ll explore why the scale of your data should be a key factor in your data quality plan and why sampling isn’t enough. We’ll also discuss why full-fidelity data quality monitoring is essential.
Understanding how volume influences data quality
Handling large volumes of data presents unique challenges, particularly when it comes to maintaining high data quality. Historically, sampling has been one of the most common approaches to managing these challenges. Sampling involves taking a small subset of the data and analyzing it to infer the quality of the entire dataset. There is extensive research into various sampling strategies, such as systematic sampling, stratified sampling, and cluster sampling, each with varying levels of success across different domains, including infrastructure monitoring.
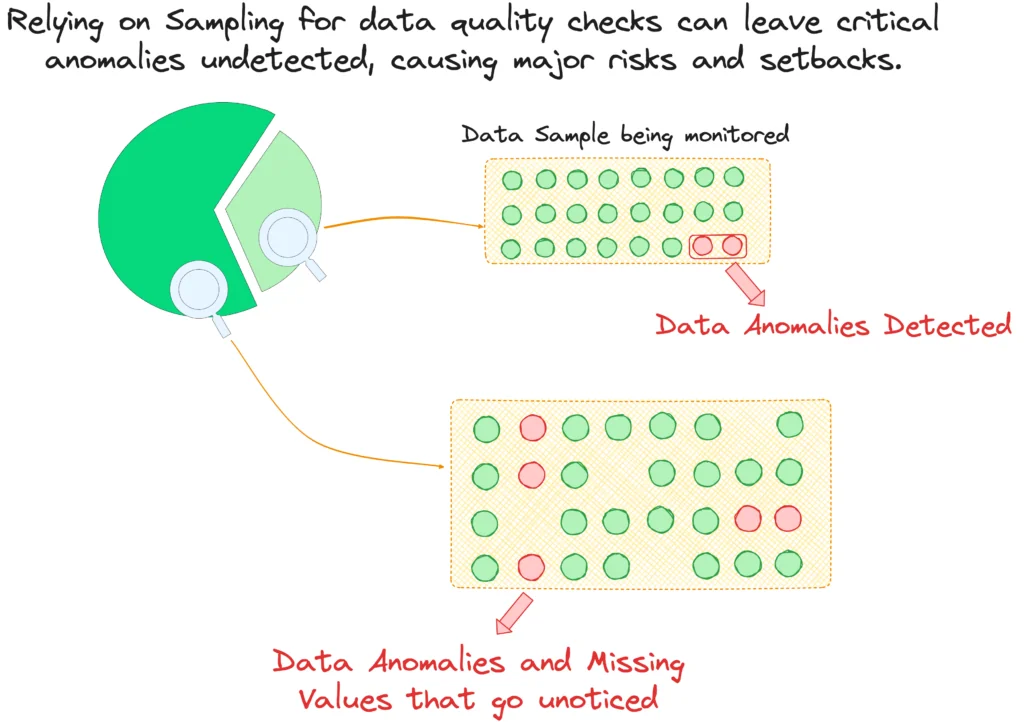
While sampling is quicker and less resource-intensive, offering a rough estimate of data quality, it has significant limitations. Sampling can miss anomalies and outliers, leading to a false sense of security. Critical issues can go undetected when only a fraction of the data is checked, potentially resulting in substantial financial losses and reputational damage.
When dealing with large volumes of data, these risks are amplified. The sheer size and complexity of data increase the chances of missing important details when relying on sampling. As data volume grows, so does the potential for hidden errors, inconsistencies, and anomalies that could impact business operations and decision-making.
How full fidelity data quality works?
A more comprehensive approach is needed to overcome sampling’s limitations. Full-fidelity monitoring ensures a complete view of data health, capturing all anomalies and providing a clear picture of data integrity. Unlike sampling, full-fidelity monitoring leaves no blind spots. It checks every piece of data, which is crucial for finding subtle or rare anomalies that sampling might miss.
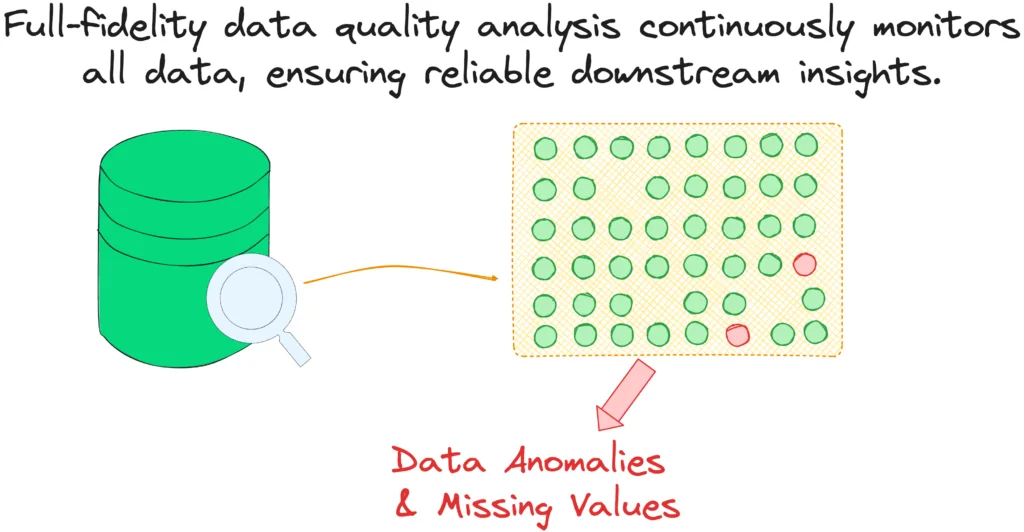
Full-fidelity monitoring requires sophisticated algorithms and architecture to manage vast amounts of data efficiently and avoid high costs. Machine learning algorithms like time series analysis play a vital role. These algorithms can learn patterns from the data collected over time without predefined rules and help identify trends, seasonal patterns, and anomalies.
Traditional approaches were built on the idea of running a number of SQL queries to extract relevant metrics from the data and then analyze them. However it only works for smaller datasets with a relatively small number of monitored attributes/metrics and hence they defaulted to sampling to process larger volumes of data. Full-fidelity relies on sophisticated algorithms and architecture to make sure vast amounts of data can be analyzed efficiently and to avoid high costs, those algorithms are highly tuned to be able analyze thousands of attributes across billions of records.
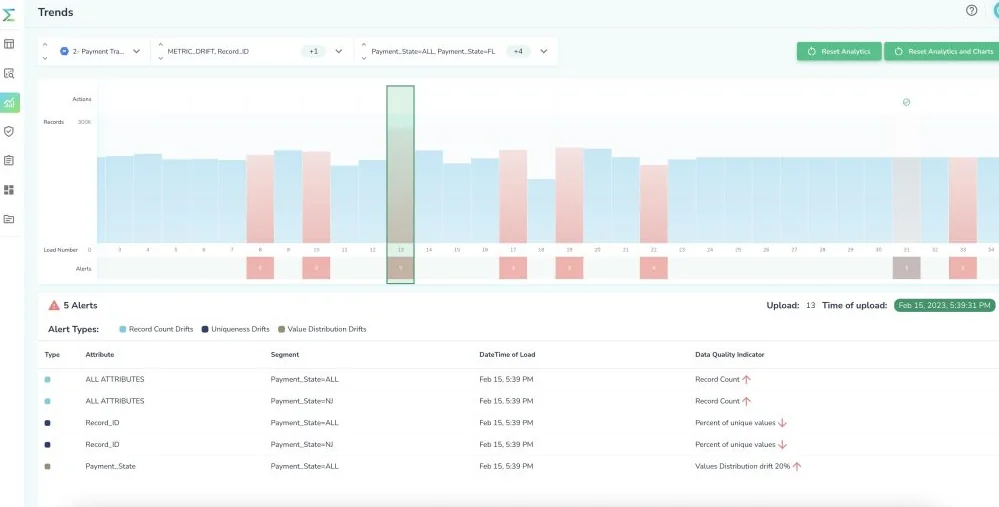
Moreover, full-fidelity monitoring ensures that the signals extracted from the data are stable and consistent with historical trends. This stability is crucial for data observability, as it helps detect unknown issues that haven’t been seen before. By continuously scanning all data, full-fidelity monitoring can identify and alert on any deviations from the norm, ensuring that any potential issues are addressed promptly.
Another crucial aspect is remediation. When using sampling, detecting a potential problem often requires manual intervention to dig deeper, perform a full assessment, and apply fixes.

This process can be time-consuming and inefficient. In contrast, a full-fidelity approach can handle remediation natively. Since all the data is processed, the findings are comprehensive, allowing for automatic remediation. For example, techniques like data binning and automatic data correction can be applied immediately. Sampling limits these options to simpler solutions, like circuit breaker patterns, which only stop the process when an issue is detected but do not fix the underlying problem.
Conclusion
In conclusion, ensuring data quality by only checking a small portion is risky and can lead to significant financial and reputational damage. Sampling often misses anomalies and outliers, especially as data volumes grow.
Full-fidelity data quality monitoring, however, captures all anomalies and provides a complete picture of data integrity. By using sophisticated algorithms and techniques like time series analysis, it ensures stable and consistent data signals. This approach also streamlines remediation by allowing automatic fixes, thus avoiding the inefficiencies of manual intervention.
Passionate about data quality? Get expert insights and guides delivered straight to your inbox – click here to subscribe to our newsletter now.
- On this page
See what’s possible with Telmai
Request a demo to see the full power of Telmai’s data observability tool for yourself.



