Why sampling based workflows lead to endless remediation cycles?
Relying on partial data for validation can quietly erode trust across your organization. When critical anomalies go unnoticed, the impact is felt in flawed decisions, delayed rollbacks, and costly cleanups. Learn why proactive, end-to-end visibility into data quality is a must-have for data-driven teams.

Sampling is often seen as a practical shortcut for data quality checks, but as discussed in our previous article, it only offers partial insights into your data. This article explores the limitations of sampling-based data quality workflows that frequently result in overlooked critical anomalies, leading to iterative resource-heavy remediation cycles.
Why does sampling trigger endless remediation cycles?
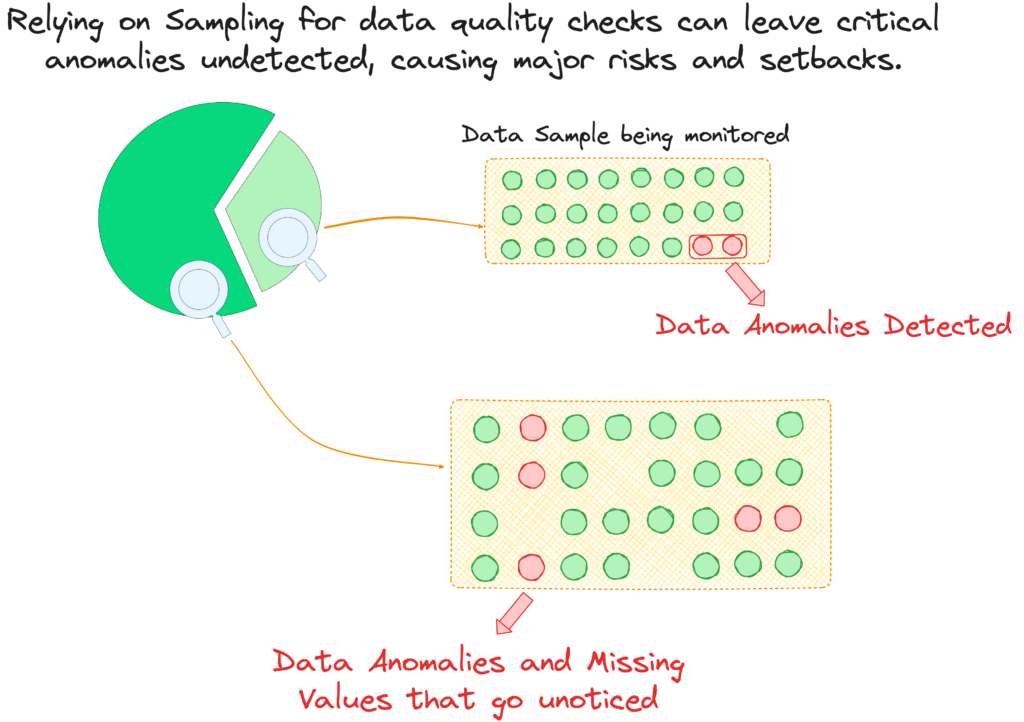
Data teams use sampling-based quality checks, processing about 5% to 10% of records. While effective at identifying surface issues like null values, they often overlook critical outliers in modern data environments.
For example, edge cases that frequently go unnoticed, such as:
- Encoding mismatches in multilingual datasets, where differences in encoding standards cause characters like ö, é, or ñ to appear as question marks or incorrect symbols. Sampling may overlook these inconsistencies, leading to corrupted customer records, failed lookups, and inaccurate text-based analytics.
- Mismatches in nested fields within semi-structured data, such as JSON records storing addresses inconsistently—some as separate fields and others as a single free-text field, leading to schema mismatches
- Pattern anomalies, such as disruptions in expected seasonal trends, often go unnoticed since small data samples may fail to capture shifts in time-series patterns, leading to forecasting errors
Even more complex edge cases are composite anomalies from derived metrics, such as customer status interacting with transaction histories, violating business rules, or producing mathematically valid but impractically impossible results due to precision loss.
Undetected issues can cascade through interconnected systems, disrupting data pipelines, skewing AI and ML outputs, and leading to unreliable insights. When these problems arise in production, teams face an endless cycle of reactive fixes, diverting resources from planned improvements and eroding stakeholder confidence in data initiatives.
The reactive reality of sampling-based DQ workflows
To understand why sampling-based data quality fails at scale, let’s examine how insurance firms specializing in business coverage struggled with pricing accuracy due to incomplete revenue and employee data.
Insurance pricing is a delicate balance—underpricing policies expose the insurer to financial risk while overpricing leads to lost customers. Business insurers rely on revenue and employee count as key risk indicators, ensuring policy pricing aligns with a company’s operational scale.

A leading insurance provider initially sampled 10% of its data to validate revenue and employee counts, assuming this subset would surface meaningful discrepancies. But sampling quickly proved inadequate:

Revenue anomalies in non-sampled high-risk businesses went undetected since sampling only covered a fraction of companies, making it impossible to flag underreported or overstated financials. This led to mispriced policies and inaccurate financial risk assessments.
Even when a company was included in the sample, historical revenue trends weren’t fully captured. This prevented the insurer from spotting gradual shifts in revenue or reductions in workforce that could signal increased risk.
Sampling skewed risk modeling by overrepresenting high-risk businesses while excluding low-risk ones. This led to inflated policy costs for safer companies and underestimated risks for insurers, increasing financial exposure.



This example highlights the fundamental flaw in sampling-based data quality workflows—no matter how much you expand the sample size or refine validation rules, you’re still working with an incomplete picture. Sampling is inherently reactive, forcing teams into a never-ending cycle of identifying issues late, patching gaps, and increasing costs without guaranteeing full accuracy. To break this cycle, organizations need a more scalable and proactive approach—one that doesn’t rely on fragmented insights but instead ensures full visibility into data accuracy at all times.
In the next section, we’ll explore how modern data quality solutions overcome these challenges by analyzing entire datasets, detecting anomalies in real-time, and enabling businesses to maintain trust in their data without costly guesswork.
How modern data quality tools address gaps left by sampling methods
Sampling-based workflows often lack the depth to handle today’s complex data environments. Modern non-sampling-based monitoring solutions like Telmai overcome these limitations by running on a compute layer adjacent to data lakes and warehouses, enabling massively parallelized processing across billions of records. This approach eliminates query overhead on underlying data systems, optimizing resource efficiency and processing speed while ensuring comprehensive end-to-end data observability.
Leveraging its open architecture, Telmai can give teams complete visibility and control over their data health by integrating it into your existing stack, including data lakes, data warehouses, streaming sources, cloud storage, and open table formats like Iceberg and Delta. Using advanced AI algorithms, Telmai continuously validates data at scale across structured and semi-structured data sources to detect inconsistencies in real-time and enables orchestration of data quality workflows, ensuring a steady stream of reliable data in your pipeline.
Conclusion
While Sampling-based workflows may seem practical, they fail to address the realities of modern data ecosystems. By missing anomalies, creating endless remediation cycles, and increasing costs, sampling-based data quality checks hinder operational efficiency, inflate budgets, and erode trust in data-driven initiatives.
Non-sampling-based data quality solutions like Telmai provide scalable, efficient, and AI-driven data quality monitoring, ensuring every data point is validated without burdening infrastructure. Telmai transforms data quality from a reactive challenge into a proactive advantage by enabling seamless integration, intelligent anomaly detection, and automated remediation.
Stop relying on partial insights. Click here to see how Telmai can future-proof your data strategy.
Passionate about data quality? Get expert insights and guides delivered straight to your inbox – click here to subscribe to our newsletter now.
- On this page
See what’s possible with Telmai
Request a demo to see the full power of Telmai’s data observability tool for yourself.