Built with Google Cloud AI: How AI can improve data quality and observability for startups and enterprises
In the modern business landscape, being a data-driven organization is crucial, with data-driven insights fueling innovation, uncovering growth opportunities, and securing a competitive edge. However, to leverage these benefits, organizations must ensure the use of high-quality, timely, and reliable data, free from errors, omissions, and duplicates.


Being a data-driven organization is vital in today’s business landscape. Data-driven insights drive innovation, identify growth opportunities, and ensure competitive advantage. But to realize these advantages, organizations must make sure they’re using high-quality data — data that’s timely and reliable, free of errors, omissions, and duplicates. Business intelligence and decision-making that runs on low-quality data can have serious implications for customers and for the business.
Data observability — a set of techniques and real-time processes that reveal whether your data contains signals that need investigating — helps ensure that your data is accurate, complete, and current, allowing your organization to make informed business decisions with high confidence. But data observability that ensures data accuracy and validity in a timely manner, particularly on large volumes of data, requires distributed computing frameworks and large-scale processing power — making Google Cloud the architecture of choice to run its data observability solution.
Data quality challenges of the modern data stack
Organizations have traditionally taken a rules-based, manual approach to ensuring data quality. But this classic approach [Figure 1] no longer meets the demands of data teams due to four key limitations:
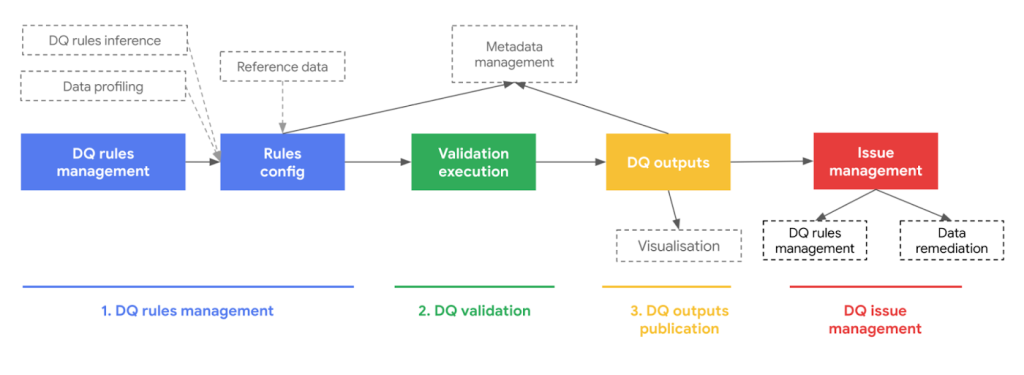
Figure 1: Traditional rules-based approach to data quality and mitigation flow
- Operational overhead: Managing rules manually is a time-consuming and inherently error-prone process. What’s more, it’s a reactive process, so data teams discover the need for a new rule only when something goes wrong.
- Cost-effective scalability: As data volume and complexity grow, it becomes more difficult to manage data quality and accuracy manually, particularly when that data is spread across multiple data storage systems. Without automation built into your processes, scaling rules-based management requires additional human and computing resources, which pushes costs higher.
- Batch and streaming data, including semi-structured data: Building data quality at scale means analyzing, discovering, and detecting issues across hundreds of tables and across all (or most) attributes within these sources, which often contain semi-structured JSON data. These types of workloads are computationally heavy. Often, a single data pipeline consists of multiple underlying source systems like data warehouses, Delta Lakes, analytic databases, and streaming systems — all of which make a rules-based approach difficult to execute and scale.
- Incomplete visibility: Rules-based data quality management assesses data against predefined metrics and alerts to issues like inconsistencies, discrepancies, and inaccuracies. But anomalies, outliers, and drifts in data can go undetected without data observability tools. These tools use machine learning and statistical analyses to learn from your data, predict issues, find root causes, and monitor changes in your data for signals worthy of investigation.
Google Cloud: A platform of choice for Telmai’s data observability platform
Built and run on Google Cloud, Telmai Data Observability Platform helps organizations monitor and manage the quality of their data by providing a centralized view of data across all data sources. Telmai’s engine performs data profiling and analysis to identify potential issues, such as missing values, duplicate records, and incorrect data types; ML-based anomaly detection to surface unexpected values in data that may indicate problems and to predict what can be reasonably expected; and continuous monitoring to detect changes in data quality over time.
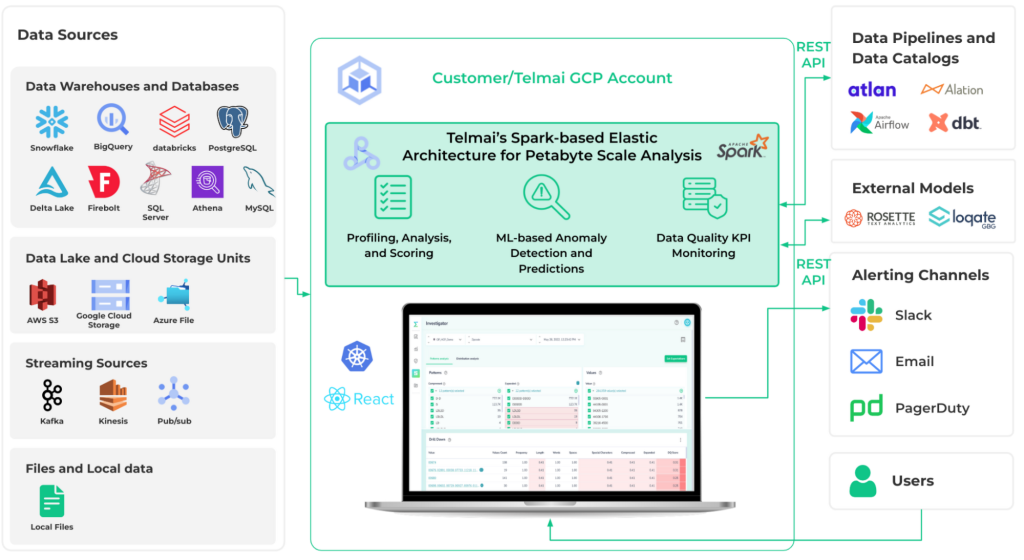
Figure 2: Telmai data quality and observability architecture with Google Cloud
To build an advanced, AI-driven architecture [Figure 2] capable of scaling and solving data quality and observability challenges, Telmai considered various cloud computing platforms. The company selected Google Cloud because Google Cloud’s managed and serverless components — including Dataproc, Pub/Sub, Google Kubernetes Engine (GKE), and BigQuery — offered the best economic and performance value. With a modern architecture on Google Cloud, Telmai’s observability solution is quick to deploy for startups and scale to enterprise use cases on demand.
By using Spark (running via Google Cloud Dataproc) as the processing engine, Telmai is able to decouple data quality analysis and anomaly detection from the underlying operational systems such as BigQuery, which offers three advantages:
- Open architecture: Telmai’s decoupled architecture enables calculating (and continuously monitoring) data quality metrics and thresholds for any kind of underlying system in customers’ data pipelines without overloading those systems. This open architecture gives data architects the flexibility to add, upgrade, or swap data systems without worrying about redesigning their data quality and observability.
- Scalability: Spark gives Telmai the ability to design highly optimized and scalable algorithms specific for data monitoring, where the traditional approach of running SQL queries fell short. A scalable architecture with elastic resources gives Telmai Data Observability Platform the ability to monitor hundreds of millions of data metrics and their trends so the solution can validate data efficiently, in parallel, and with high throughput — for example, data with 100 million+ rows of JSON structures of 1,000+ attributes. Relying on Dataproc service provides resilience and ease of operation at scale; clusters autoscale, spin up, and stop when required. This keeps solution costs down for customers.
- Security and operations: Google Cloud provides a high level of control for security. Security ranges from basic-level measures like multi-factor authentication, single sign-on, key store, granular roles, and ease of separating development from production environments, to more sophisticated measures such as Security Command Center to track and remediate vulnerabilities.
Human error is one of the biggest security risks for any organization, so it’s critical to define and operate infrastructure as code to standardize deployments and minimize the chances of misconfigurations or exposures. By leveraging Kubernetes and GKE, Telmai not only further reduces such risk but also runs Telmai deployments with low effort in customers’ accounts entirely (private cloud option), ensuring that all data stays within their safe perimeter.
These benefits provided Telmai with exceptional speed in development, particularly in supporting new integrations. By utilizing managed services such as Dataproc and GKE, Telmai can concentrate on building its application instead of managing the software. The infrastructure, auto-scaling, security, DevOps, and other essential services are easily accessible to Telmai through the Google Cloud stack.
Google Cloud and Telmai: Partners in data observability
Google Cloud is helping technology companies like Telmai build innovative applications on Google’s data cloud with simplified access to technology, helpful and dedicated engineering support, and joint go-to-market programs.
Learn more about Google Cloud’s open and innovative generative AI partner ecosystem and about Telmai and Google Cloud.
Passionate about data quality? Get expert insights and guides delivered straight to your inbox – click here to subscribe to our newsletter now.
- On this page
See what’s possible with Telmai
Request a demo to see the full power of Telmai’s data observability tool for yourself.