Building open data lakehouses with Apache Iceberg, Delta Lake, and Apache Hudi
In this article learn how Apache Iceberg, Delta Lake, and Apache Hudi enhance data lakes through open architectures. It details their benefits in flexibility, performance, and scalability, and explores key features such as ACID transactions, time travel, and schema evolution, making them ideal for modern data management.

Lately, there has been a lot of buzz regarding open data formats, like Apache Iceberg or Databricks Delta Lake. So why is it a big deal, and why should you consider them part of your data architecture? While they are different in design, both are intended to allow the use of tools/technology of choice, are best suited for particular tasks, and, most importantly, operate with the same copy of the data, greatly simplifying the architecture. Simplicity often means robustness. Keeping these formats open allows the engineering community to enjoy compatibility with anything required to solve a task. And did I mention it’s all designed to scale? But first, let’s look under the hood.
What are table formats?
Table formats bridge data lakehouses, data lakes, and databases by providing a database-like interface to scattered data files. Instead of dealing with multiple files individually, table formats let us treat related files as one unified dataset or “table” – similar to what you’d find in a traditional database.
Data lakehouses typically contain information spread across numerous files. While tools like Spark and Flink allow us to analyze this data using languages such as Python, R, Scala, and Java, table formats simplify this process by treating these scattered files as one cohesive unit. This table-based approach is particularly valuable since it enables SQL querying, making data analysis more accessible to a broader audience.
What is Apache Iceberg?
Apache Iceberg was originally developed by Netflix in 2018 to address the challenges associated with managing large-scale data lakehouses within the Apache Hadoop ecosystem. It was donated to the Apache Software Foundation and has since evolved into a community-driven project.
Iceberg tables introduce a level of abstraction that allows for efficient querying, data versioning, and schema management. Here are the key components of Iceberg tables:
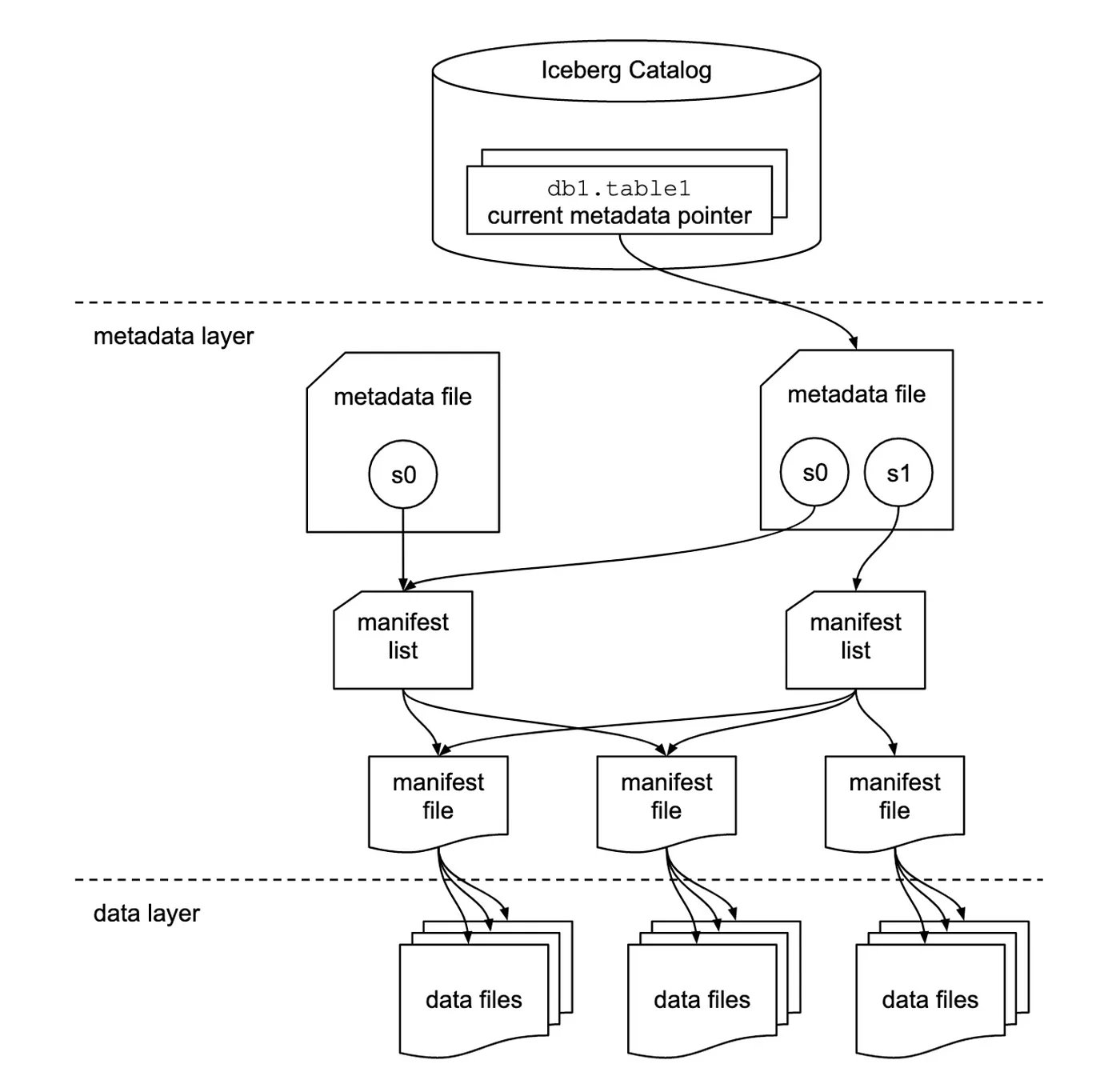
- Schema Evolution: Iceberg supports schema changes without requiring the rewriting of data files. This feature is crucial for long-term data management.
- Partition Evolution: It allows partitions to evolve over time, allowing to run queries more efficiently.
- Time Travel: Iceberg’s time travel feature enables users to query historical data and roll back changes, ensuring data integrity and reproducibility.
- ACID Transactions: Ensures transactional consistency, allowing multiple applications to safely operate on the same data set simultaneously.
Iceberg tables serve data engineers, analysts, and architects by providing a flexible and reliable way to manage large data lakehouses. By supporting open standards, Iceberg enables interoperability between different data processing engines, thereby fostering an open architecture.
What is Delta Lake?
Delta Lake, developed by Databricks, is another modern table format designed to bring ACID transactions to data lakehouses. While it shares some similarities with Iceberg tables, such as supporting schema evolution and time travel, it has distinct differences in design and implementation.
Delta Lake tables are structured to enhance data reliability and performance within data lakehouses. Here are their key components:
- ACID Transactions: Ensures data reliability and consistency across multiple operations.
- Schema Enforcement and Evolution: Delta tables enforce schema constraints, which helps maintain data quality.
- Time Travel: Like Iceberg, Delta tables allow for querying historical data and data versioning.
- Compaction and Optimization: Delta tables optimize data storage by compacting small files into larger ones, improving query performance.
Delta tables also promote open architecture by integrating with various data processing tools and platforms. This flexibility makes them suitable for organizations looking to maintain an open data ecosystem.
What is Apache Hudi?
Initially developed at Uber, Apache Hudi (Hadoop Upserts Deletes and Incrementals) is an open-source data management framework that simplifies incremental data processing and provides real-time data access for large-scale data lakes. It supports various storage formats, such as Apache Parquet and ORC, enabling efficient data ingestion and storage management.
Hudi integrates seamlessly with big data ecosystems, ensuring that data lakes remain up-to-date with the latest data changes while offering features like ACID transactions, indexing, time travel, and schema evolution for robust data management. Here are their key components:
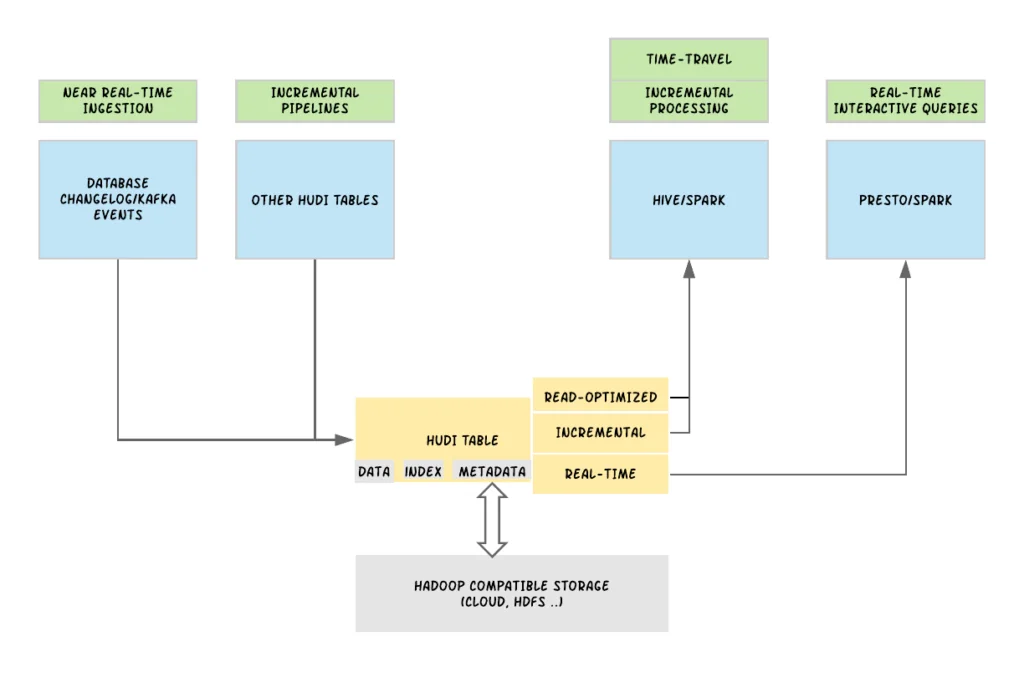
- Incremental Data Processing: Hudi supports efficient data ingestion by processing only the changed data, reducing processing time and resource consumption.
- ACID Transactions: Ensures data consistency and reliability, crucial for real-time updates and deletions.
- Indexing: Built-in indexing speeds up data retrieval and avoids full dataset scans, enhancing query performance.
- Time Travel: Enables users to query historical data versions, essential for auditing, debugging, and ensuring data reproducibility.
- Schema Evolution: Allows schema changes without rewriting the entire dataset, providing flexibility for long-term data management.
Key comparisons between Iceberg,Delta Lake and Hudi tables
Performance and Scalability: Iceberg optimizes metadata handling and query planning to enhance performance, Delta Lake focuses on compaction and optimization strategies to improve query speed, while Hudi emphasizes incremental data processing for real-time analytics, significantly reducing processing time and resources.
Schema Evolution: Iceberg allows metadata updates without altering data files, providing long-term flexibility. Delta Lake enforces schema constraints to maintain data quality, and Hudi supports seamless schema changes without the need to rewrite entire datasets, ensuring efficient data management.
Time Travel and Versioning: All three formats—Iceberg, Delta Lake, and Hudi—support time travel, enabling users to query historical data states for auditing, debugging, and data accuracy checks.
ACID Compliance: Iceberg uses immutable table snapshots for consistent transactions, Delta Lake ensures reliability and consistency across operations, and Hudi maintains data integrity with ACID transactions during real-time updates and deletions, which is crucial for maintaining accurate and consistent data.
Conclusion
Apache Iceberg, Databricks Delta, and Apache Hudi support open architectures, making them essential tools in today’s data ecosystem. Their open-source nature and compatibility with various processing engines make them versatile choices for organizations seeking interoperability. Features like ACID transactions and schema enforcement ensure compatibility with tools for different workloads, including data ingestion, analytical queries, and ML pipelines. These table formats enable seamless integration, reduce complexity, and avoid vendor lock-in, empowering organizations to manage their data more effectively.
Understanding and leveraging formats like Apache Iceberg, Delta Lake, and Hudi can help you achieve greater data management efficiency. However, this also requires data observability and quality to be natively compatible with those formats and able to handle the schema complexity and scale that come with their adoption. Try Telmai today to experience the benefits of comprehensive data observability and confidently make informed decisions.
Passionate about data quality? Get expert insights and guides delivered straight to your inbox – click here to subscribe to our newsletter now.
- On this page
See what’s possible with Telmai
Request a demo to see the full power of Telmai’s data observability tool for yourself.



