How to ensure data quality in streaming data pipelines
Streaming data pipelines enable real-time data flow from source to destination, allowing instant analysis and response to events. With speed comes new data quality challenges and new solutions to keep everything under control.


In recent years, we’ve witnessed an unprecedented surge in event-based data transactions, fuelled by the proliferation of Internet of Things (IoT) devices, the explosive growth of e-commerce, and instantaneous financial transactions. Each click, purchase, or sensor reading generates a stream of data. The velocity and volume of this data stream have outpaced the capabilities of traditional batch-based data pipeline systems. Traditional batch-based data pipelines are designed to process data in chunks at scheduled intervals. Such systems often falter under the weight of accumulated data, are unable to meet the stringent Service Level Agreements (SLAs), can’t deliver the timely information businesses require, or simply cost too much. Streaming data pipelines have emerged as a pivotal solution to address this gap.
What are streaming data pipelines?
Streaming data pipelines, or event stream processing, is a data pipeline design pattern where data flows constantly from a source to a destination and is processed in real-time. This allows applications to act quickly on data streams and trigger immediate responses.
The architecture of a typical streaming data pipeline is structured around several critical components:
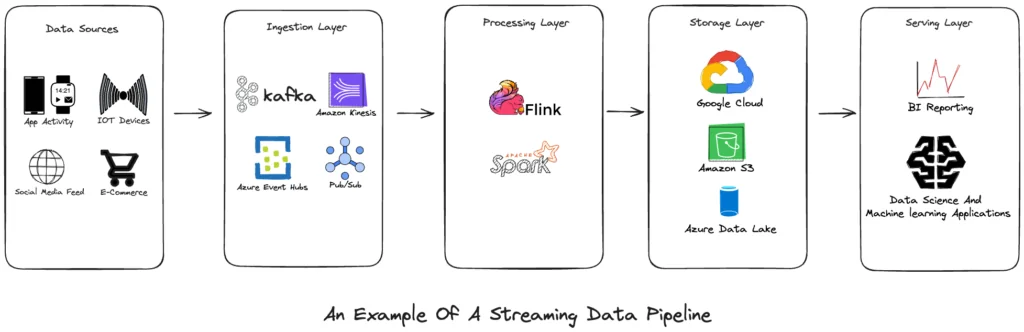
- Data Sources: These are the starting points of the data journey, originating from a variety of real-time generators that feed the pipeline with a continuous stream of varied data. In this pipeline, sources include user interactions from mobile apps, telemetry from IoT devices, dynamic social media feeds, and transactional activity from e-commerce platforms.
- Ingestion Layer: Serving as the gateway to the pipeline, this layer is responsible for capturing and routing the data into the system. Robust and scalable technologies like Apache Kafka, Amazon Kinesis, Azure Event Hubs, and Google Pub/Sub are employed to manage the high throughput of incoming data flows efficiently.
- Processing Layer: At the core of the pipeline, the processing layer is where the data is refined and transformed. Tools such as Apache Spark and Apache Flink are used here for their real-time processing capabilities. They apply business logic, filter noise, aggregate streams, and transform data into a format ready for analysis and storage.
- Storage Layer: Processed data needs to be stored, and this is where databases and data lakes come into play. Depending on the requirements, a variety of storage solutions can be used, including distributed file systems like HDFS, cloud storage services like Amazon S3, Azure Data Lake, Google Cloud Storage, or real-time databases like Apache Druid or Google Bigtable, which provide scalable and accessible storage options.
- Serving Layer: The insights derived from the processed data are made actionable in this final stage of the pipeline. Data is served through BI tools for reporting and visualization, aiding business analysts in decision-making. Additionally, data scientists and machine learning engineers utilize the processed data for predictive modeling and to power AI-driven applications, thereby closing the loop of the data pipeline by converting data into strategic value.
From batch to stream: addressing the challenges
Transitioning to streaming data pipelines represents a fundamental shift in how data is processed and analyzed which introduces its own set of challenges. Employing traditional tactics in streaming contexts often leads to repeated, costly data queries to ensure integrity, a resource-intensive and expensive process. Efforts to refine this through strategies like data partitioning might introduce complexity, resulting in systems that are tough to manage and scale.
Moreover, the integration of streaming data pipelines with existing data infrastructure poses another layer of complexity. Traditional databases and data warehouses may not be optimized for real-time data streams, requiring significant modifications or adopting new technologies compatible with streaming data. This integration process can be time-consuming, technically challenging, and costly, especially for organizations with extensive legacy systems.
Another critical issue is the unpredictability of data volume flowing through the system. Unlike telemetry data, which shows some predictability, analytics data often sees unpredictable spikes, necessitating the need for a scalable and adaptable solution. Over-preparing for peak scenarios can cause inefficiencies and unnecessary expenses, highlighting the importance of a flexible strategy to navigate the complexities of streaming data efficiently.
Simplify real-streaming data with Telmai

Addressing the crucial need for seamless real-time data processing without overloading current infrastructures, Telmai stands out as the ideal solution for allowing businesses to harness the full potential of their data.
Telmai’s approach involves directly consuming data from the message bus, thereby allowing for immediate analysis, remediation, and generating alerts through configurable micro-batching. This strategy avoids unnecessary data scans at the destination and ensures that data integrity and quality are maintained without imposing additional strain on the underlying data infrastructure.
Furthermore, Telmai’s engine, based on Spark, offers a versatile solution that seamlessly integrates with both streaming and batch data applications. This provides users with a consistent experience and powerful capabilities across different data processing scenarios. The deployment within a Virtual Private Cloud (VPC), coupled with operation through a control plane, guarantees that data remains secure, mitigates the risk of incurring egress costs, and eliminates the need for manual capacity planning and maintenance.
Discover how Telmai can revolutionize your data ecosystem, making it more dynamic and value-driven. Request a demo of Telmai today.
Passionate about data quality? Get expert insights and guides delivered straight to your inbox – click here to subscribe to our newsletter now.
- On this page
See what’s possible with Telmai
Request a demo to see the full power of Telmai’s data observability tool for yourself.